How I Store Mutable HTML Files on the Edge (AWS)
I've recently made the decision to go (mostly) fully static on my Next.js website and to host my content on the "edge". Up till now I've been storing my immutable static files (eg CSS, JavaScript & images) on the edge but wanted to do the same for my HTML files so I can get sub 40ms responses. I'm aiming for that "instant" load feel. This was easier said than done, as always, with AWS, and this post outlines the approach I settled on.
To begin let's understand the main requirement of serving HTML content: it should never be cached by the browser, to allow users to consume new content.
HTML files are mutable, they can be changed and are likely to change often. You can say the same for CSS & JavaScript, but we cache those files by adopting a filename hashing strategy where each static file has a unique hash in the filename. We cannot do this for HTML files, because we cannot change the URL's that point to the HTML files. HTML urls must be static. This is the crux of the problem, "how do we cache dynamic content on the edge?"
Next let's briefly understand the tools we'll end up using. If you're using AWS it makes sense to use S3 to store your assets and CloudFront to serve them.
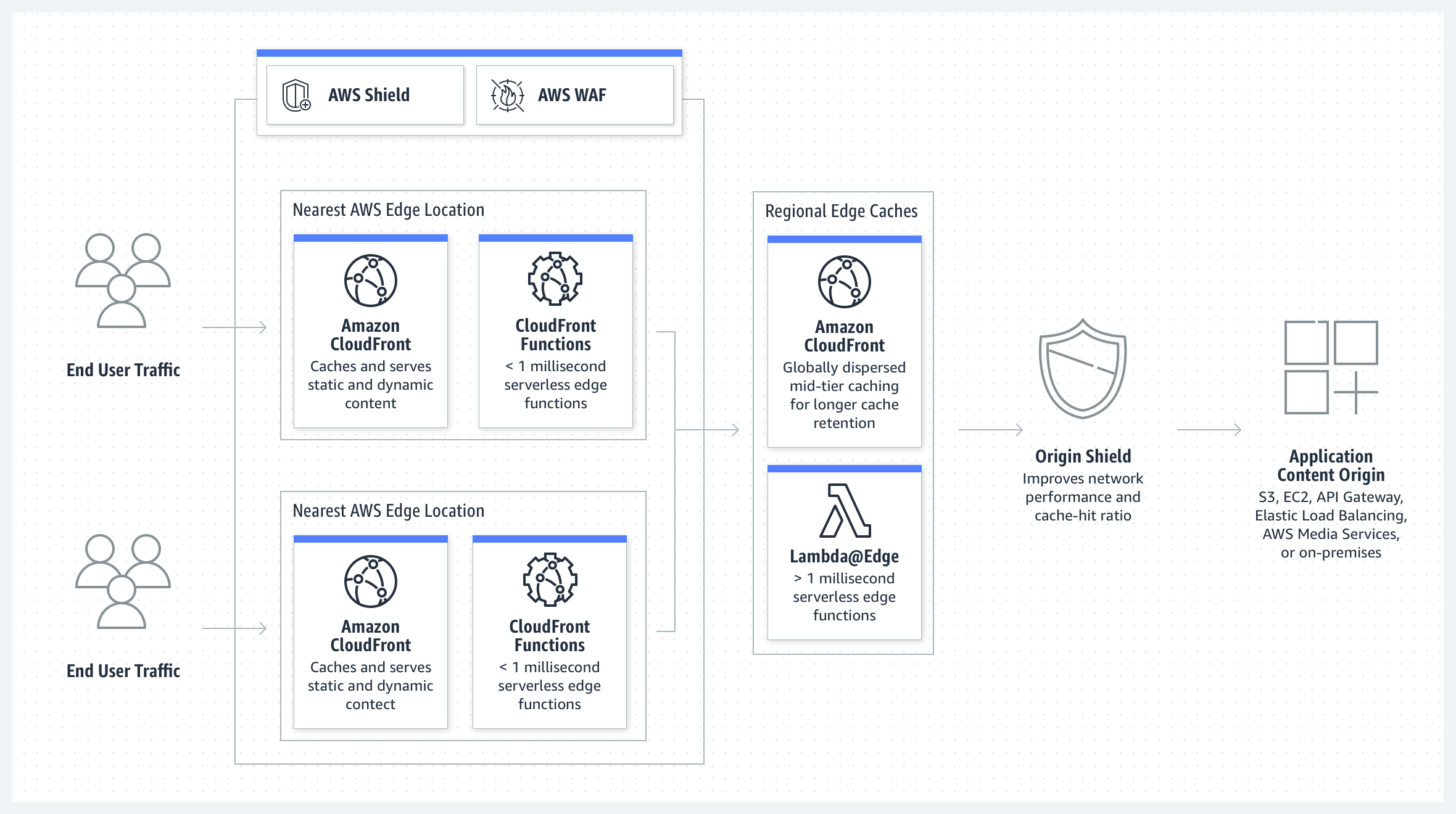
CloudFront is essentially a caching layer. "Edge
caching" means the content is served from a caching server
located closest to you. AWS has many edge servers and so is a good
choice for caching content. CloudFront uses origin (eg S3) cache
headers to determine if it should cache on the edge, and if it
finds Cache-Control: no-cache it simply will not
cache this content. To prevent browsers from caching dynamic
content, we need to send Cache-Control: no-cache (or
similar) from the origin (S3), but then how do I store my mutable
HTML files on the edge?
The solution becomes apparent when you understand that CloudFront can use a different set of (non-standard) Cache headers to control what is cached in the Edge. This is what I ended up doing:
- Set no-cache headers for the browser
- Set edge cache headers to store content on the edge
- Invalidate edge cache on new deployments
This way the browser will ALWAYS ask for new content, but the edge will always serve cached content.
You can achieve the above using the maxage (browser)
and s-maxage (edge) headers, for example:
max-age=0,s-maxage=31536000. This tells the browser
to always request new content, but tells CloudFront to cache on
the edge for 1 year. Have a read of
Managing how long content stays in the cache
for more information.
The next part is invalidating the edge cache on deployment.
Tooling Update (19/12/2021): I've created separate GitHub Actions to deploy my site to S3 and invalidate the CloudFront cache:
- badsyntax/github-action-aws-s3
- badsyntax/github-action-aws-cloudformation
- badsyntax/github-action-aws-cloudfront
I use the aws cli to do this, eg
aws cloudfront create-invalidation --distribution-id 12345
--invalidation-batch file://invalidate-batch.json
but this requires a JSON file with a list of files to invalidate.
I use the following
basic node script
to generate this file:
const path = require('node:path');
const glob = require('glob');
const rootDir = path.resolve(__dirname, '..', 'out');
glob(`${rootDir}/**/*.html`, {}, processFiles);
function processFiles(err, files) {
if (err) {
console.error(err);
process.exit(1);
}
const filePaths = files.map((file) =>
file.replace(rootDir, '').replace('.html', '').replace('/index', '/')
);
const invalidationBatch = {
Paths: {
Quantity: filePaths.length,
Items: filePaths,
},
CallerReference: `invalidate-paths-${Date.now()}`,
};
console.log(JSON.stringify(invalidationBatch, null, 2));
}
The script above is straightforward, it generates the JSON file by
listing all HTML files generated within the Next.js
out directory. It can potentially be improved by only
invalidating cache for HTML files that have changed but
there's a bit of complexity in determining modified HTML
files.
And now for the final problem, url rewrites, or lack of them on
S3. For example, we want to route the URL /about to
the file /about.html and as far as I'm aware you
can't do that on S3. The "quick fix" for this is to
add a
trailing slash, but I don't like the trailing slash. The solution I
settled on is to literally create a file called
/about (without any extension, and with the same
headers as the file with extension).
I use an extremely basic bash script that uses the aws cli to copy all html files to new files without an extension:
#!/usr/bin/env bash
out_path=$1
bucket=$2
cd "$out_path" || exit
find . -type f -name '*.html' | while read -r HTMLFILE; do
htmlfile_short=${HTMLFILE:2}
htmlfile_without_extension=${htmlfile_short::${#htmlfile_short}-5}
# cp /about.html to /about
aws s3 cp "s3://${bucket}/${htmlfile_short}" "s3://${bucket}/$htmlfile_without_extension"
if [ $? -ne 0 ]; then
echo "***** Failed renaming build to ${bucket} (html)"
exit 1
fi
done
This is all done is my GitHub Action workflow, for example:
- name: Sync assets to S3
if: (github.event_name == 'push' && github.ref == 'refs/heads/master') || github.event_name == 'repository_dispatch'
run: |
aws s3 sync out/_next s3://${{ secrets.AWS_S3_BUCKET }}/_next --cache-control public,max-age=31536000,immutable --size-only
aws s3 sync out/site-assets s3://${{ secrets.AWS_S3_BUCKET }}/site-assets --cache-control public,max-age=31536000,immutable --size-only
aws s3 sync out s3://${{ secrets.AWS_S3_BUCKET }} --cache-control public,max-age=0,s-maxage=31536000,must-revalidate --exclude "*" --include "*.html"
- name: Rename HTML files
if: (github.event_name == 'push' && github.ref == 'refs/heads/master') || github.event_name == 'repository_dispatch'
run: |
./scripts/copy-s3-html-files.sh out ${{ secrets.AWS_S3_BUCKET }}
- name: Invalidate Cloudfront Cache
if: (github.event_name == 'push' && github.ref == 'refs/heads/master') || github.event_name == 'repository_dispatch'
run: |
node scripts/generate-html-paths-cloudfront-invalidate.js > invalidate-batch.json
cat invalidate-batch.json
id=$(aws cloudfront create-invalidation --distribution-id ${{ secrets.CLOUDFRONT_DISTRIBUTION_ID }} --invalidation-batch file://invalidate-batch.json | jq -r '.Invalidation.Id')
aws cloudfront wait invalidation-completed --distribution-id ${{ secrets.CLOUDFRONT_DISTRIBUTION_ID }} --id "$id"
Once a new deployment has succeeded, no HTML files will be in the edge cache, and the first time they are requested Cloudfront will fetch the origin content from S3, then cache it. That initial origin request is going to be slow and there's not much we can do about that. I explored the possibility of pre-warming the edge cache but there's so many edge locations I decided this was impractical.
The result:

Hopefully you've found this article useful. If you find all of this a little too complex and you'd prefer to use an abstraction to do all of this for you, there are many options available like Vercel & Netlify. Personally I enjoy doing this all by myself to allow me to have more granular control over the edge caching and for me to have a better understanding on all of this. Feel free to leave a comment below with any questions or suggestions.
(No comments)